What do we do in our lab ?
The IR-NLP Lab at the Faculty of Computer Science, Universitas Indonesia, focuses mainly on the research areas of Information Retrieval, Speech Processing, and Computational Linguistics, which form a basis or foundation for a broad range of applications such as Text Mining Applications, Natural Language Processing tools, Machine Translation, Question-Answering System, Digital Libraries, and Knowledge Management.
Research Topics and Projects
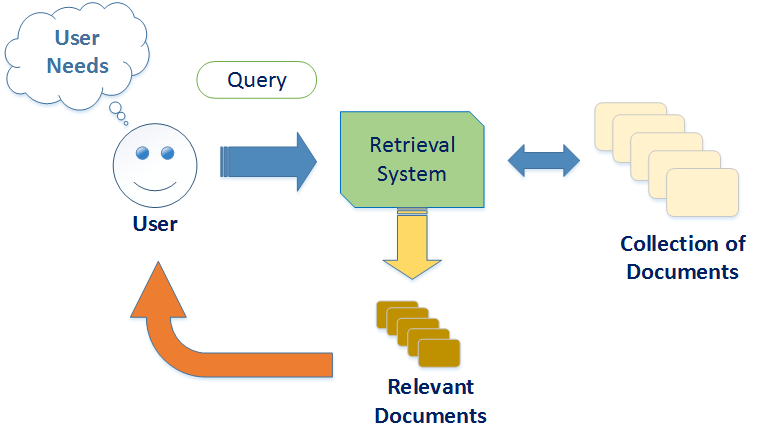
Information Retrieval
Information Retrieval seeks to explore the methods and techniques of organizing, representing, storing, and searching of information in textual and multimedia forms (speech, image, and music).
In our lab, we have conducted several research topics (as well as published several papers) in the area of information retrieval:
- Cross Language Information Retrieval
- Geographic Information Retrieval
- Music Information Retrieval
- Image Retrieval

Natural Language Processing
Natural Language Processing is a field which tries to model natural language in formal rule representation, or formalism grammar. This representation can be categorized into phonetics, morphology, syntax, semantics, and discourses. These models are implemented as softwares which can process language artifacts, including utterance, sentences, text documents, etc.
We have developed several NLP tools, especially for Indonesian Language, such as:
- Indonesian Stemmer
- Morphological Analyzer
- Part-of-Speech Tagger
- Named Entity Recognizer
- etc.

Language Resources Development
Indonesian Language is still considered as an Under-resourced Language, which means that we are still lack of language resources to support most of the natural language processing tools.
In our lab, we are also developing several language resources such as:
- Indonesian Treebank
- Indonesian WordNet
- Lexicon(KBBI)
- Text Corpus (Microblog Corpus, Parallel Corpus, etc.)
- Speech Corpus
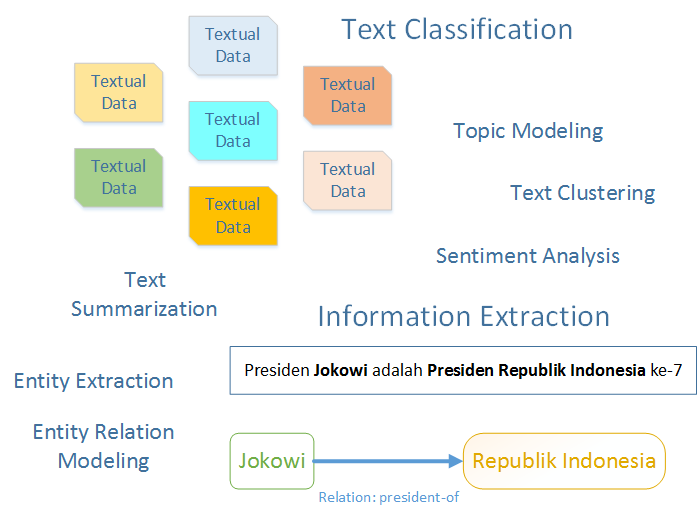
Text Mining and Knowledge Management
Text Mining seeks approaches for structuring textual data, deriving patterns from the structured textual, and finally interpreting the results as well as mining useful information from the results.
We have been doing research on the following areas of text mining:
- Text Summarization
- Text Classification
- Text Clustering
- Sentiment Analysis
- Information Extraction
- Text Mining on User Generated Contents (UGC)
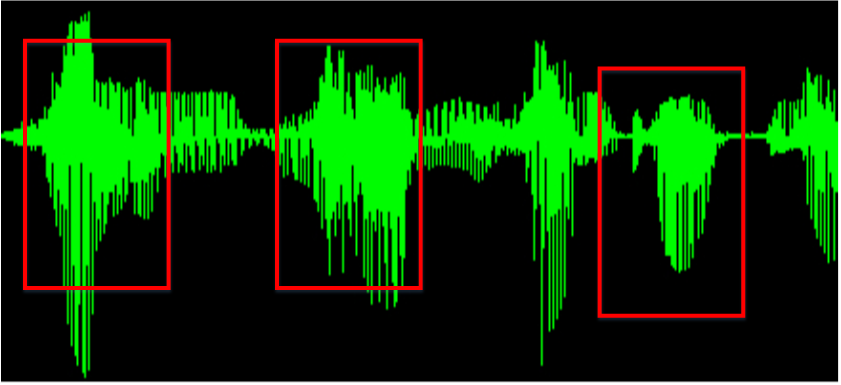
Speech Processing
In our lab, we have been doing research on Automatic Speech Recognition (ASR) that enables the recognition and translation of speech or spoken language into text. This area incorporates disciplines from computational linguistics and electrical engineering.
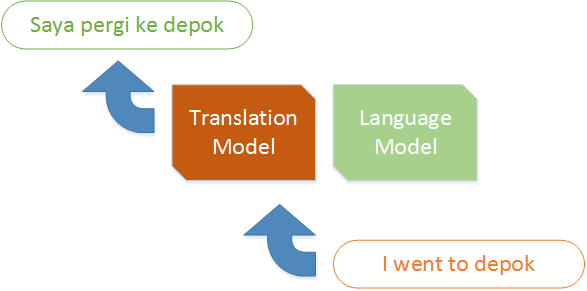
Machine Translation
Machine Translation is a sub-field of computational linguistics that seeks computational models to automatically translates text or speech expressed in one language to another language. Information Retrieval Lab has been publishing several works in this area, especially for Indonesia-English translation.