Tutorial ini hanya ditujukan jika Anda sudah mengikuti tutorial RNNs awal. Potongan kode yang ada di halaman ini hanyalah tambahan kode saja dari kode yang ada di tutorial sebelumnya.
Pada kuliah sebelumnya, proses komputasi yang terjadi pada Recurrent Neural Networks (RNNs) adalah sebagai berikut.
Sekarang, kita akan tambahkan Attention Mechanism pada bagian output RNNs sehingga dalam penentuan label dari sebuah input kalimat, masing-masing kata mempunyai kontribusi (bobot attention) yang berbeda-beda. Kita akan coba mengimplementasikan model attention yang mirip dengan Raffel dan Ellis [1] (attention pada bagian ujung sequence, tanpa konteks). Secara matematis, persamaan komputasi RNNs di atas ditambahkan dengan persamaan berikut:
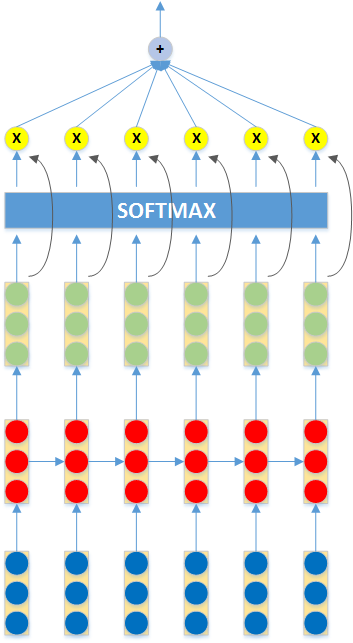
Pertama, tambahkan potongan kode berikut di dalam fungsi add_variables(.) yang sudah Anda implementasikan sebelumnya.
# attention layer
with tf.variable_scope('attention'):
A = tf.get_variable('A', [output_size, 1])
ba = tf.get_variable('ba', [1], initializer=tf.constant_initializer(0.0))
Lalu, Anda perlu mendefinisikan fungsi yang akan membungkus komputasi dari attention layer.
# attention layer
# rnn_outputs: bobot attetion & tensor 2D (num_steps,output_size)
def attention(rnn_outputs):
with tf.variable_scope('attention', reuse=True):
A = tf.get_variable('A', [output_size, 1])
ba = tf.get_variable('ba', [1], initializer=tf.constant_initializer(0.0))
#hitung weights softmax, setelah dikali matrix, lalu di softmax pada axis = 0
#karena inputnya adalah tensor 2D (num_steps, 1)
#weights adalah tensor 2D (num_steps, 1) yang berisi bobot untuk masing-masing posisi timesteps
#[[0.1], [0.15], ..., [0.3]] -> total harus 1
weights = tf.nn.softmax(tf.matmul(rnn_outputs, A) + ba, dim = 0)
# kali bobot ke output
weighted_outputs = weights * rnn_outputs
return weights, weighted_outputs
Kemudian, fungsi inference(.) yang sudah diimplementasikan sebelumnya perlu di-update menjadi sebagai berikut.
# sentence di parameter adalah list of word index, contoh: [3, 0, 4, 45, 3, ...]
# membangun computational graph untuk satu kalimat, dari input hingga output
def inference(sentence):
# sekarang, sentence adalah tensor 2D (num_steps, embed_size)
sentence = embed_lookup(sentence)
# layer RNN
rnn_outputs = rnn(sentence)
# beri bobot attention
_, rnn_outputs = attention(rnn_outputs)
# Average Pooling
#avg_outs = avg_pool(rnn_outputs)
# Sum Poooling
sum_outs = sum_pool(rnn_outputs)
# Terakhir, Logreg Classifier
logreg_outs = logreg(sum_outs)
return logreg_outs
Kemudian, kita juga perlu membuat fungsi yang mengembalikan bobot attention untuk setiap kata ketika kita sedang mengklasifikasikan sebuah kalimat.
# fungsi untuk melibat bobot attention setiap kata dari sebuah kalimat
def see_weights(sentence):
with tf.Graph().as_default(), tf.Session() as sess:
# Restore trainable parameters
add_variables()
saver = tf.train.Saver()
saver.restore(sess, "rnn.model")
sentence = embed_lookup(sentence)
rnn_outputs = rnn(sentence)
weights, _ = attention(rnn_outputs)
print (sess.run(weights))
Terakhir, kita coba training sekali lagi, lalu coba klasifikasi beberapa kalimat. Untuk beberapa kalimat yang lain, kita coba lihat bobot attention-nya untuk melihat siapa yang paling berpengaruh dalam penentuan label kelas tersebut.
# prediksi
# dari training data
predict(v.to_idx(['laptop', 'suka', 'banget']))
predict(v.to_idx(['film', 'buruk']))
# instance baru
predict(v.to_idx(['suka', 'laptop', 'dan', 'bagus']))
see_weights(v.to_idx(['suka', 'laptop', 'dan', 'bagus']))
predict(v.to_idx(['film', 'mengecewakan']))
see_weights(v.to_idx(['film', 'mengecewakan']))
predict(v.to_idx(['film', 'bagus']))
see_weights(v.to_idx(['film', 'bagus']))
[1] Colin Raffel, Daniel P. W. Ellis, Feed Forwar Networks with Attention Can Solve Some Long-Term Memory Problems, Workshop track - ICLR 2016