Pada tutorial kali ini, kita akan mencoba membuat representasi vektor dari kata dengan model Word2Vec (CBOW atau Skip-Gram) oleh Mikolov et al., [1]. Tutorial ini mengasumsikan bahwa Anda sudah mengikuti kuliah terkait distributional semantic models sebelumnya. Sebagai review, model CBOW mencoba untuk memproyeksikan vektor kata-kata konteks (w_{t-1}, w_{t+1}) untuk memprediksi vektor kata target w_{t}. Sedangkan, model Skip-Gram adalah kebalikannya, yaitu mencoba memprediksi vektor kata-kata yang ada di konteks (w_{t-1}, w_{t+1}) diberikan vektor kata tertentu w_{t}. Dari sini, model CBOW cenderung lebih mudah smooth terhadap informasi distribusional karena semua kata-kata konteks langsung diproses menjadi satu vektor sebelum akhirnya digunakan untuk memprediksi vektor kata target. Oleh karena itu, untuk corpus yang lebih kecil ukurannya, model CBOW cenderung lebih baik. Sebaliknya, model Skip-Gram membuat sepasang kata target dan konteks sebagai sebuah instance sehingga Skip-Gram cenderung lebih baik ketika ukuran corpus sangat besar. Kali ini, kita akan menggunakan Gensim untuk implementasi dari Word2Vec. Lain kali, jika ada panjang umur, saya akan membuat tutorial untuk membangun berbagai macam metode untuk membuat representasi vektor dari dasar dengan, misal, tensorflow.
Pertama-tama, kita perlu import terlebih dahulu berbagai macam library untuk pekerjaan kita kali ini. Perhatikan bahwa PCA (Principal Component Analysis) dan matplotlib akan digunakan untuk melakukan plotting vektor kata ke bidang 2 dimensi. Kita akan memvisualisasikan beberapa kata dan melihat kedekatannya satu sama lain.
import gensim
import numpy as np
import os
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA, KernelPCA
Kemudian, kita akan membuat wrapper class untuk membaca setiap file teks pada korpus, dan juga membaca baris demi baris pada file teks secara efisien. Hal ini dapat dicapai dengan penggunaan generator yield pada python. Dengan fitur ini, kita tidak perlu memuat seluruh teks pada korpus di memori sebelum melatih model Word2Vec kita.
class MySentences(object):
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
#untuk setiap file
for fname in os.listdir(self.dirname):
#untuk setiap baris
for line in open(os.path.join(self.dirname, fname)):
yield line.split()
Berikutnya adalah menghidupkan object dari kelas iterator corpus tersebut. Perhatikan bahwa corpus Anda harus diletakkan di dalam sebuah folder yang didefinisikan pada argumen berikut (misal, folder corpus). Letakkan semua file teks corpus di dalam folder tersebut.
sentences = MySentences('./corpus') # a memory-friendly iterator
Kemudian, bagian berikut adalah intinya, yaitu melatih model Word2Vec kita menggunakan corpus dan juga corpus iterator yang sudah kita definisikan sebelumnya. Penjelasan argumen yang penting ada di bagian komentar.
# sg = 0 -> CBOW, sg = 1 -> skip-gram
# size: dimensionality dari vektor kata yang dihasilkan
# min_count: banyaknya frekuensi miminal sebuah kata, jika ingin dipertimbangkan dalam proses
# window: range antara kata-kata konteks dengan posisi current word
model = gensim.models.Word2Vec(sentences, size=32, sg = 0, min_count = 1, window = 5, iter = 10)
Jika Anda ingin menyimpan model yang sudah Anda latih, serta memuat model yang sebelumnya disimpan, Anda dapat menggunakan potongan kode berikut.
# save model
model.save('./mymodel')
# load model
new_model = gensim.models.Word2Vec.load('./mymodel')
Potongan kode berikut adalah beberapa API yang disediakan oleh gensim untuk kebutuhan operasi vektor, seperti menghitung kemiripan vektor antara 2 kata, dan yang lainnya.
# mendapatkan representasi vektor dari sebuah kata
print (model.wv['dia'])
# menghitung similarity vektor antara dua kata
print (model.wv.similarity('dia', 'kita'))
# mencari top-N similar words
print (model.wv.similar_by_word('kita', topn=10, restrict_vocab=None))
Plotting Word Vectors
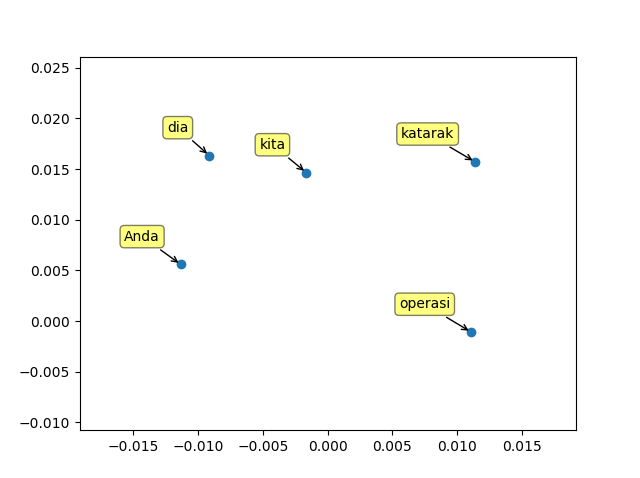
Sekarang, kita coba plot vektor dari beberapa kata untuk melihat visualisasi kedakatan vektor dari beberapa kata. Kata-kata yang ingin Anda tampilkan plot vektornya dapat Anda letakkan pada variable word_list berikut.
# kata-kata yang ingin kita plot vektornya
word_list = ['kita', 'dia', 'Anda', 'operasi', 'katarak']
# daftar vektor dari kata-kata tersebut
word_vectors = np.array([model.wv[w] for w in word_list])
Selanjutnya, kita agar bisa di-plot di bidang 2 dimensi, kita perlu melakukan reduksi dimensi vektor kata ke vektor 2 dimensi. Kita dapat menggunakan berbagai macam teknik seperti PCA (Principal Component Analysis) dan t-SNE.
# reduksi dimensi vektor ke 2D agar bisa di-plot pada bidang 2D
dimred = PCA(n_components=2, copy=False, whiten=True)
red_word_vectors = dimred.fit_transform(word_vectors)
Terakhir, kita buat fungsi untuk melakukan plot vektor dari kata-kata tersebut (yang sudah direduksi ke dimensi 2).
def plot(datas, labels, fc='yellow'):
# plot the dots
plt.subplots_adjust(bottom = 0.1)
plt.scatter(datas[:, 0], datas[:, 1], marker='o')
# annotate labels
for label, x, y in zip(labels, datas[:, 0], datas[:, 1]):
plt.annotate( \
label, \
xy=(x, y), xytext=(-15, 15), \
textcoords='offset points', ha='right', va='bottom', \
bbox=dict(boxstyle='round,pad=0.3', fc=fc, alpha=0.5), \
arrowprops=dict(arrowstyle = '->', connectionstyle='arc3,rad=0'))
plt.show()
# kita plot !
plot(word_vectors, word_list)
[1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.